【注目記事】
・SEの転職体験談 | 受託開発から自社製品開発へ ・SIer勤務のSEがパソナキャリアに相談してみた ・SIer勤務のSEがマイナビエージェントに相談してみた
SQLに慣れていない人には、CASE式は扱いづらい存在だと思います。
でも、CASE式を上手く利用すると、SQLをシンプルにしたり、パフォーマンスを改善できたりします。
この記事では、CASE式を活用したパフォーマンス改善の方法をご紹介します。
※実行環境は全てSQL Serverです。
目次
なぜCASE式は扱いづらいのか
SQLの初心者がCASE文を扱いづらいと感じる理由は、プログラミングで最初に学習するJavaなど手続き型のプログラミング言語と考え方が異なるからです。
手続き型のプログラミング言語は、文単位で処理を考えます。一方SQLでは、式単位で考えます。
文と式の違いはこちらの記事が分かりやすいです。
- 手続き型言語の単位は「文」
- 文は一文一文ごとに「実行」される。実行の結果は「副作用」によってのみ表現できる
- 副作用とは「世界を汚すこと」。手続き型言語は副作用の連続でプログラムが進行していく
- 汚せる範囲を「スコープ」と呼ぶ
- 関数型言語の単位は「式」
- 式は「評価」され、「値」(戻り値)を返す
- 「式」の評価結果は本来「戻り値」のみであるが、関数型言語の種類によっては副作用を起こすこともできる(関数型言語でも戻り値を無視して手続き型言語のように副作用の連続でプログラムを書くこともできる)
- いっぽう副作用を起こさず式の戻り値のみでプログラムを書く純粋関数型言語というものもある
- 別に純粋関数型言語がエライと言いたいわけじゃないけど、「その処理が世界を汚していないか」を意識してプログラムを書くことはとても大事
- ちなみに Python では評価 (eval) と実行 (exec) で分かれていて、eval は戻り値を返すけど exec は戻り値を返さないといった感じで式と文が明確に分かれている
- Ruby からプログラミングを入門した人は式と文についてあまり意識していないかもしれないとふと思ったので、こういう記事を書いたのであった
- 違うプログラミング言語もやってみると色々と気づきがあって楽しいですよ
手続き型のプログラミング言語では、条件分岐する時には、IF文などの文単位で処理を考えます。
その考えでSQLを書こうとすると、SELECT文をもとに分岐させようとします。
しかし、SQLは宣言型の言語で、基本的な単位は「式(Expression)」です。
そのため、条件分岐もCASE式で実現します。
この基本的な考え方の違いが、CASE式のとっつきにくさの原因だと思います。
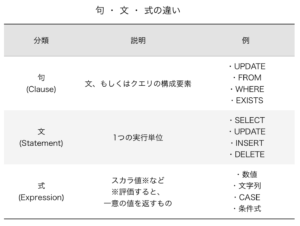
【補足】SQLの句・文・式の違い
(参考 | 【用語解説】わかりにくいSQLの句・文・式の違い)
CASE式 vs UNION句
プロはSELECTで分岐する
実験用のデータベースを作成します。
実験用のテーブルを用意します。
学生の情報を管理するテーブルで、年齢、好きなアルコール、好きなジュースの情報をもっています。
テーブルのイメージ
| No | Name | Age | Alcohol | juice |
| 1 | test1 | 33 | ワイン オレンジジ | ュース |
| 2 | test2 | 19 | ワイン コーラ | |
| 3 | test3 | 23 | ワイン オレンジジ | ュース |
| 4 | test4 | 26 | ワイン コーラ | |
| 5 | test5 | 20 | ビール オレンジジ | ュース |
| 6 | test6 | 35 | ビール オレンジジ | ュース |
実験用のテーブルに100万件のデータを登録します。
ここから、CASE式とUNION句を実行計画や処理時間を比較します。
クエリの内容は、20歳以上なら、好きなアルコールを表示し、20歳未満なら好きなジュースを表示します。
まずはUNION句の場合
処理時間
CPU 時間 = 766 ミリ秒、経過時間 = 9189 ミリ秒
実行計画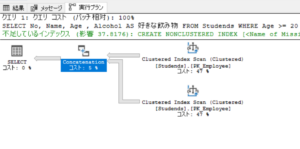
UNION句はインデックスのスキャンが2回実行されています。
UNION句を利用すると、このように条件ごとにテーブルをスキャンする無駄が生じます。
続いてCASE式の場合
処理時間
CPU 時間 = 516 ミリ秒、経過時間 = 8751 ミリ秒。
経過時間が400ミリ秒ほど短くなりました。
実行計画
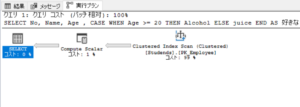
テーブルのインデックススキャンが1回になり、処理が簡略化されました。
条件が1つなので、処理時間や可読性に大きな違いがありませんが、条件が増えるほど差が大きくなります。
集計の条件分岐
条件によって集計する場合も、CASE式を利用できます。
SUMの中にCASEを記載し、○○の条件を満たせ加算するという形で記載します。
次の例は、年齢ごとに、ビール好きの人数と、コーラ好きの人数を集計しています。
集約の結果に対する条件分岐
GROUP BYで集約した結果に対して、UNION句とHAVINGをつかって条件分岐を実現できますが、CASE式を使えば、より少ないコード、より少ない処理時間で済みます。
下記は、年齢ごとに、ビールを飲む人数を3段階で評価するクエリです。
UNION句を使うケース
条件分岐はできる限りCASE句を使用すべきだと書きましたが、UNION句を使うケースはあります。
まず、マージするSELECT分同士で、使用するテーブルが違う場合は、CASE式を使えません。結合すれば使うことはできますが、その場合結合するコストがかかるので、UNION句で実現するのとどちらが良いか一概にいえません。
また、UNION句の方がパフォーマンスが良いケースがあります。
それは、UNION句であれば、インデックスが使用でき、それ以外の場合は使用できないケースです。
その場合は、複数回のインデックススキャン(UNION句)と、1回のテーブルフルスキャン(CASE式)の比較になり、テーブルの状態によっては、UNION句を使用した方がパフォーマンスが良いことがありえます。
参考書籍
SQLスキルを高めるためのおススメ書籍
SQLのスキルを高めるには、学校の試験勉強と同じように多くの問題を解いてみるのが効率的です。
『スッキリわかるSQL入門 第2版 ドリル222問付き! (スッキリシリーズ)』は、SQLの基本的な内容の解説に加え、200問を超える問題が掲載されているので、SQL初心者が学習に使うのにおススメです。
実際、この書籍を新卒1年目の新人さんに2-3週間かけて取組んでもらったことがあり、書籍を読んだ後に簡単なSQLの改修を任せましたが、基本的な部分にはつまずかずに改修を進められました。

コメントを残す